


网关简单调用链监控
作为服务聚合和对外服务的网关,我们的业务模型主要是:

我们再简化一下这个通信模型,能够得出如下的通信模型:
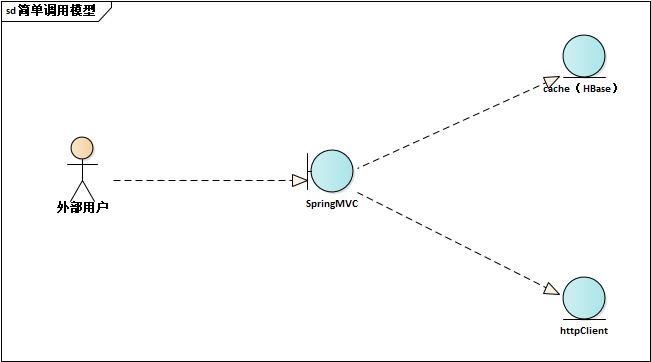
所以我们主要需要关注的对象有:
- SpringMVC:接收/响应外部请求的时间戳以及是否正确返回结果
- cache:是否命中cache,以及cache对应的开始结束时间戳
- httpClient:请求的开始/结束时间戳,以及返回的结果,主要包括通信结果(http code)、业务结果(如果可以确定)
如果我们能把上述的每一次请求走过的链路的数据记录下来,并通过特定的key进行关联(例如requestInId),那么我们就能够建立起来简单的调用链跟踪。
目标
纵向建立请求到入站到返回结果的完整调用链条,至少包括每个核心步骤(controller、cache、httpclient)的关键数据,例如:
- 开始时间
- 调用结果
- 是否查得数据
- 结束时间
- 参数
- 异常信息
横向能够查询每个核心步骤(controller,cache,httpclient)的独立调用统计数据,例如:
- 调用总量
- 成功数量/失败数量/查得数量
- 调用耗时统计(max,min,avg,tp)
- 异常类型以及数量
通过以上两种结构的数据,我们就可以:
- 可以针对单次调用进行异常分析
- 监控各个接口健康状况,用于预警和性能优化
- 作为计费以及收益/成本计算的凭据
技术选型
调用链监控目前的理论基础目前比较完善,诞生了一些标准的实现,例如open tracing( https://opentracing.io/ ),也有一些开源的实现,例如Zipkin(https://github.com/openzipkin/zipkin)、pinpoint(https://github.com/naver/pinpoint)、skywalking(https://github.com/apache/incubator-skywalking)等等,所以不管是理论还是实践目前都相对已经完善。
对于我们来说,如何构建一个调用链监控系统,主要有以下的衡量点:
- 自研
- 优势
- 非常贴合我们的业务需求(例如对于第三方接口,我们不仅需要知道成功与否,还需要在业务上去排查成功/失败甚至是否查得数据)
- 便于和公司其他系统整合
- 可以不用太考虑通用性,开发模型相对简单
- 构建过程中能够锻炼和提升团队能力
- 劣势
- 研发成本大周期长,成本太高
- 在稳定版本之前,有很长的调试和优化的时间
- 优势
- 使用开源套件
- 优势
- 节省研发成本
- 总体来说比较稳定,特别是有大量生产环境样例的开源产品
- 生态较好,有大量的第三方扩展插件可以使用
- 劣势
- 开源项目都是通用需求,需要一定的二次开发,二次开发对于研发能力的要求较高而且要求曲线比较陡峭
- 同其他系统集成有一定的成本
- 优势
自研
对于自研调用链监控来说,主要有几个核心业务:
- traceId,spanId模型:这个可以直接参考open tracing规范
- 调用链上下文环境传递
- 内部:依托于ThreadLocal或者slfj规范的MDC均可以实现基于线程的上下文传递,不过需要关注的是如果有线程切换的,需要通过切向(动态代理/字节码)实现上下文的传递,特别是各种异步编程中
- rpc:我们大部分都是httpClient,直接通过header即可以实现上下文的传递
- 持久化及查询
- 由于调用链监控往往意味着很大的数据量,所以需要选用合适的大数据容器
- ElasticSearch:目前来看最适合作为调用链监控的持久化容器,本身查询非常强大,原生支持复杂查询条件、count、tp性能查询
- Hbase:和ES一样都拥有对于大数据的支持,性能甚至超过ES,不过因为本身存储结构的问题,对于单条调用链存储非常合适,但是复杂查询支持较差,统计功能也比较弱,如果能够自己构建额外的索引来辅助查询也没有问题
- mysql/postgresql:查询功能强大,但是对于大数据支持比较弱,需要大量的分库分表操作,postgresql能够原生支持集群,在横向扩展方面比mysql还要稍微强大一点,缺点就是对于跨库跨表查询的操作非常麻烦,不过用sharding-jdbc的话会缓解不少
- 时序数据库:时序数据库适合用来存储元数据变化不大,但是值随着时间频繁变化的内容,所以用来做耗时统计比较合适,但是对于调用链本身的内容存储比较弱
- 由于调用链监控往往意味着很大的数据量,所以需要选用合适的大数据容器
- ui:需要基础的查询和结果展示界面,可能还需要其他(例如认证等)通用界面
第三方开源项目
这里介绍一下常见的调用链监控开源方案:
- Zipkin:仅仅构建了基本的调用链监控的模型,对于数据的采集和持久化支持比较差,全部依赖第三方组件支持(少且通用性差),需要大量的二次扩展开发来做数据采集
- pinpoint:已经有基本的调用链监控以及jvm实例监控内容,但是界面比较杂乱,代码设计和质量也参差不齐,二次开发成本稍高
- skywalking:目前相对来说比较成熟比较活跃的开源项目,基本覆盖了大部分场景(例如dubbo,springCloud,httpclient,等大量组件和中间件)的调用链跟踪,也有针对jvm的监控,项目本身设计也不错(参考:http://note.youdao.com/noteshare?id=ca20c5cc37fb0327095fc4d74c89037b&sub=32BA4628ADF040F38403FFF3246D7DB0 )
针对我们的场景,例如还需要添加cache和httpclient更加细致的结果检测,这些都需要在掌握这些开源项目之后,再做针对的二次开发,对人员的要求较高。