


HDFS中文件系统的定制
HDFS本身有Hadoop Compatible File Systems机制来进行hdfs-client级别的HDFS协议兼容,方便非HDFS存储服务也能拥抱HDFS生态,例如经典的Amazon S3,那么这块内容到底是如何实现的呢?
FileSystem
在HDFS客户端中,最核心的操作单元就是FileSystem这个核心类,它封装了绝大部分常用的文件操作,其核心机理包括:
- 提供最多configuration、URI、user三个参数的多态初始化参数,方便加载不同的FileSystem实现类
- FileSystem通过URI中的scheme来适配对应的FileSystem实现类,适配方式为className=fs.${scheme}.impl配置项或者classLoader查找FileSystem的实现类然后比对scheme
- FileSystem通过反射实例化具体的实现类后,通过调用实现类的initialize方法进行实现类的初始化
- 默认情况下,FileSystem会维护一个全局的缓存池,以保证同一个URI的FileSystem为单例,避免重复实例化浪费系统资源
在官方HDFS客户端中,我们常见的core-site.xml中名为fs.defaultFS的配置项一般会配置为hdfs://serviceName或者hdfs://host:port,其中hdfs即为scheme。FileSystem基类会通过org.apache.hadoop.fs.FileSystem#loadFileSystems方法加载几种常用的FileSystem的实现类,并通过org.apache.hadoop.fs.FileSystem#getScheme方法获取其scheme,例如scheme为hdfs的实现类就是我们熟悉的DistributedFileSystem,后续FileSystem会通过反射实例化DistributedFileSystem,并通过uri和configuration初始化以完成DistributedFileSystem的完整实例化,最终将可用的FileSystem实例返回给用户
ViewFS
在所有的FileSystem实现类中,有一个特别的FileSystem,那就是org.apache.hadoop.fs.viewfs.ViewFileSystem,详情可以参考官方文档 ViewFs Guide ,其内部会构建一颗InodeTree来维护一个虚拟的目录树,通过InodeDir来将InodeTree的某个目录绑定到特定的FileSystem,这样在对该目录进行操作的时候,所有的操作都会映射到对应的FileSystem,最终达到将多个不同的的FileSystem逻辑上整合为一个文件系统的目的:
- ViewFileSystem会读取配置文件中的mountTable配置,通过配置内容构建InodeTree的树形结构和mountPoints的具体挂载清单(两者数据内容是一致的,只是数据结构形式不同,一个为树形结构一个为列表)
- 属性结构或者具体挂载清单中的内容均为org.apache.hadoop.fs.viewfs.InodeTree.INodeLink,其内容主要为挂载目录和目录绑定的对应文件系统
- ViewFileSystem在根据mountTable加载文件系统时,会根据配置通过FileSystem基类实例化对应scheme的FileSystem(参考org.apache.hadoop.fs.viewfs.InodeTree#createLink),所以ViewFs在整合不同的FileSystem时并不受到scheme的约束
- ViewFs由于其本身的局限性,如果是跨FileSystem的操作(例如rename操作)会被拒绝
FileContext
HDFS不仅提供基于FileSystem的方式来进行文件的访问,同时还提供一个更加符合VFS标准的FileContext方式来屏蔽底层不同的实现,提供一种标准的文件操作体验:
- FileContext会通过AbstractFileSystem作为基类访问文件系统,AbstractFileSystem更加贴合操作系统API/VFS,而FileSystem更偏向于面向用户侧,将复杂的底层API进行了抽象提供了更多易用的API
- 所以如果一个scheme期望在FileContext得到支持,不仅需要提供基于FileSystem的实现,还要提供基于AbstractFileSystem的实现
- AbstractFileSystem与FileSystem实现的业务功能基本一致,主要是在提供的接口方面有稍许区别
其他文件系统实现
在进行我们自己的scheme开发之前,我们也可以稍微了解一下目前HDFS官方默认提供的几种FileSystem/AbstractFileSystem,既能够让我们做出的产品更加贴合HDFS生态,又能极大的降低开发成本:
- RawLocalFileSystem(FileSystem): 基于本地文件的FileSystem,file scheme的默认实现,支持路径的映射
- FilterFileSystem(FileSystem): FileSystem的委托机制的实现,其内部需要引入一个真正的委托FileSystem,所有的外部请求都会转发给委托FileSystem
- FilterFs(AbstractFileSystem): 类似于FilterFileSystem,其内部也有一个委托AbstractFileSystem,所有的外部请求都会转发给委托AbstractFileSystem
- DelegateToFileSystem(AbstractFileSystem): 比较特别的一个AbstractFileSystem,上文我们介绍过FileSystem和AbstractFileSystem的区别,可以理解为两个都是基础的文件系统,只是API的设计有不同的侧重,这个实现就是打通AbstractFileSystem和FileSystem,降低scheme支持FileContext的开发成本
实现一种新的scheme
所以如果我们要实现一种新的基于本地文件系统的scheme,结合HDFS本身已经提供的物料,那么最简单的方案参考:
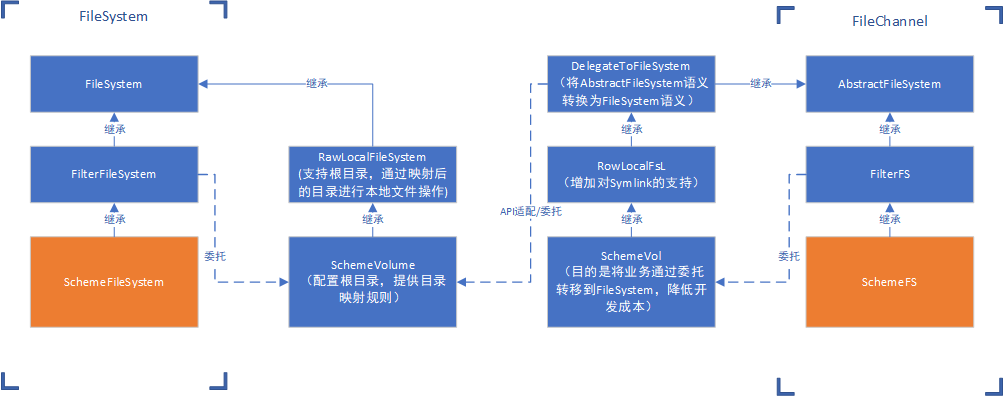
整个方案有两个入口类:SchemeFileSystem以及SchemeFs,分别用于适配FileSystem和AbstractFileSystem来覆盖HDFS的标准FileSystem以及FileContext场景,核心的实现类为SchemeVolume,其中包含了绝大部分定制内容,同时其本身继承于RawLocalFileSystem,可以直接使用HDFS本身已经提供的本地文件操作业务,最终SchemeFileSystem和SchemeFS都会将所有的业务请求通过委托转发给SchemeVolume,整套实现案例可以参考glusterfs-hadoop
局限性
通过上述方式新增scheme虽然简单快捷,但是在具体操作中却有较大的局限性,主要体现在:
DFSAdmin
DFSAdmin即是我们常用的hadoop/hdfs dfs命令的执行者,但是其在执行过程中却对FileSystem有严格的约束:
//org.apache.hadoop.hdfs.tools.DFSAdmin#getDFS
protected DistributedFileSystem getDFS() throws IOException {
FileSystem fs = this.getFS();
if (!(fs instanceof DistributedFileSystem)) {
throw new IllegalArgumentException("FileSystem " + fs.getUri() + " is not an HDFS file system");
} else {
return (DistributedFileSystem)fs;
}
}
DFSAdmin必须要是DistributedFileSystem或者其子类才能正常使用,这就要求在做schema扩展时,FileSystem实现必须继承DistributedFileSystem才能获得DFSAdmin的赋能
多命名空间的兼容
如果scheme要通过支持多个FileSystem实例来支持不同的服务,例如挂载不同的本地目录作为不同的HDFS服务,那么可以使用URI中的HOST/PORT来进行标记区分:
- 在FileSystem的实例化过程中,第一步为通过反射以Configuration作为参数进行实例化,之后会通过URI作为参数调用FileSystem的org.apache.hadoop.fs.FileSystem#initialize方法进行初始化
- 在AbstractFileSystem的实例化过程中,最终都会通过URI和Configuration两个参数进行实例化
//org.apache.hadoop.fs.AbstractFileSystem#newInstance static <T> T newInstance(Class<T> theClass, URI uri, Configuration conf) { T result; try { Constructor<T> meth = (Constructor<T>) CONSTRUCTOR_CACHE.get(theClass); if (meth == null) { meth = theClass.getDeclaredConstructor(URI_CONFIG_ARGS); meth.setAccessible(true); CONSTRUCTOR_CACHE.put(theClass, meth); } result = meth.newInstance(uri, conf);//这里直接调用了一个不在默认构造函数的构造方法,实现内需要支持这种构造方式 } catch (Exception e) { throw new RuntimeException(e); } return result; } - 所以不论是在FileSystem还是AbstractFileSystem中我们都可以获取到文件系统的URI,而URI中有几个重要的属性:scheme、host、port、authority、userInfo,其中host/port就是一个可以很好的标记不同的服务的标记,HDFS HA也是基于host来进行不同HDFS服务的区分的