


SpringCloud调研报告
经过之前的一次分享和讨论,我们决定使用SpringCloud作为我们的微服务基础框架,所以我们花了一段时间对整个SpringCloud的生态进行了一次调研,也对一些基础组件进行了测试和不同技术选型的对比。
SpringCloud的基础组件
SpringCloud有大量的组件,具体可以参考 SpringCloud官方网站,虽然看起来多且杂,但是就微服务来说,我们主要关注的还是几个核心方面:
- 服务发现
- eureka
- consul
- RPC调用
- ribbon
- hystrix
- openFeign
- 扩展组件
- sleuth
- zuul
服务发现(Eureka/Consul)
首先开宗明义,目前标准的SpringCloud服务发现机制是有非常大的缺陷,主要来自于服务的部署和提供的服务的完全绑定,主要的场景是:
- 业务初期的时候,一般都会遵循最小开发/部署的原则,在开发的时候业务模块划分的粒度可能比较粗,而在部署的时候可能会将多个服务集中部署在一个JVM实例。当服务的复杂度持续上升的时候,服务才会慢慢细化拆分,而一旦上游服务进行拆分,如果部署和提供的服务进行了过多的绑定,就会影响下游
Eureka vs Consul
从功能上来看,Eureka更专注于服务发现本身,而Consul则更关注于生态,提供一些其他组件/特性:
- 监控检查(不仅是简单的存活,还包括一些其他的例如内存/CPU等运行环境指标
- Key-Value容器:分布式的KV服务,提供HTTP API
- 安全证书管理
- 多数据中心支持
不过Consul大部分业务均有更加专业的开源组件提供服务,所以我们其实也更关注于它的服务发现。
集群支撑
Consul和Eureka均有本身的集群支撑模式,不过实现的方式和结果存在较大的差异,Consul采用类似于Zookeeper的leader+选举制度,采用raft保证一致性(即只要n/2+1的实例的结果一致则认为最终一致),所以对一致性有非常高支持,同时raft本身的简单和高效也能够支撑集群管理的性能;而Eureka采用的是Eureka节点之间定时互相通信将各自的服务节点互相共享。这就是经常能看到Consul和Eureka对比里面的所谓的CAP(Consistency 一致性、 Availability 可用性、Partition tolerance 分区容错性)原则里CA和AP的区别。
不过因为服务发现本身的对于时效性和一致性要求均不高,毕竟实例变化不会经常有,所以两者就服务发现集群本身来看,差异不是太大,都能满足需求。
部署与业务分离
正如之前所说,SpringCloud在部署和业务分离上天然的缺陷,所以Eureka也继承了这种思路,而且在实现上也非常简单,没有域、namespace等这些常见的管理层次,仅仅是完全根据serviceId(也就是springBoot中的spring.application.name)。而Consul本身在这方面则明显更多的参考现在通用的设计,服务和部署完全隔离,同时还有更多的监控管理内容,不过这部分和更加专业的例如zabbix又显得不足。
不过不论是Eureka还是Consul,由于SpringCloud的整个服务发现的流程的设计是使用spring.application.name作为serviceId,导致两者在提供的服务上都没有本质的区别,只是选择CA还是AP的区别而已。
综上,在不考虑后续扩展的情况下,在SpringCloud的框架上使用Eureka或者Consul没有太大的区别,而在Eureka已经放弃开发2.0的情况下,选择设计理念更先进的Consul,不论是为后续扩展开发做准备亦或是积累Consul运维经验都是不错的选择。
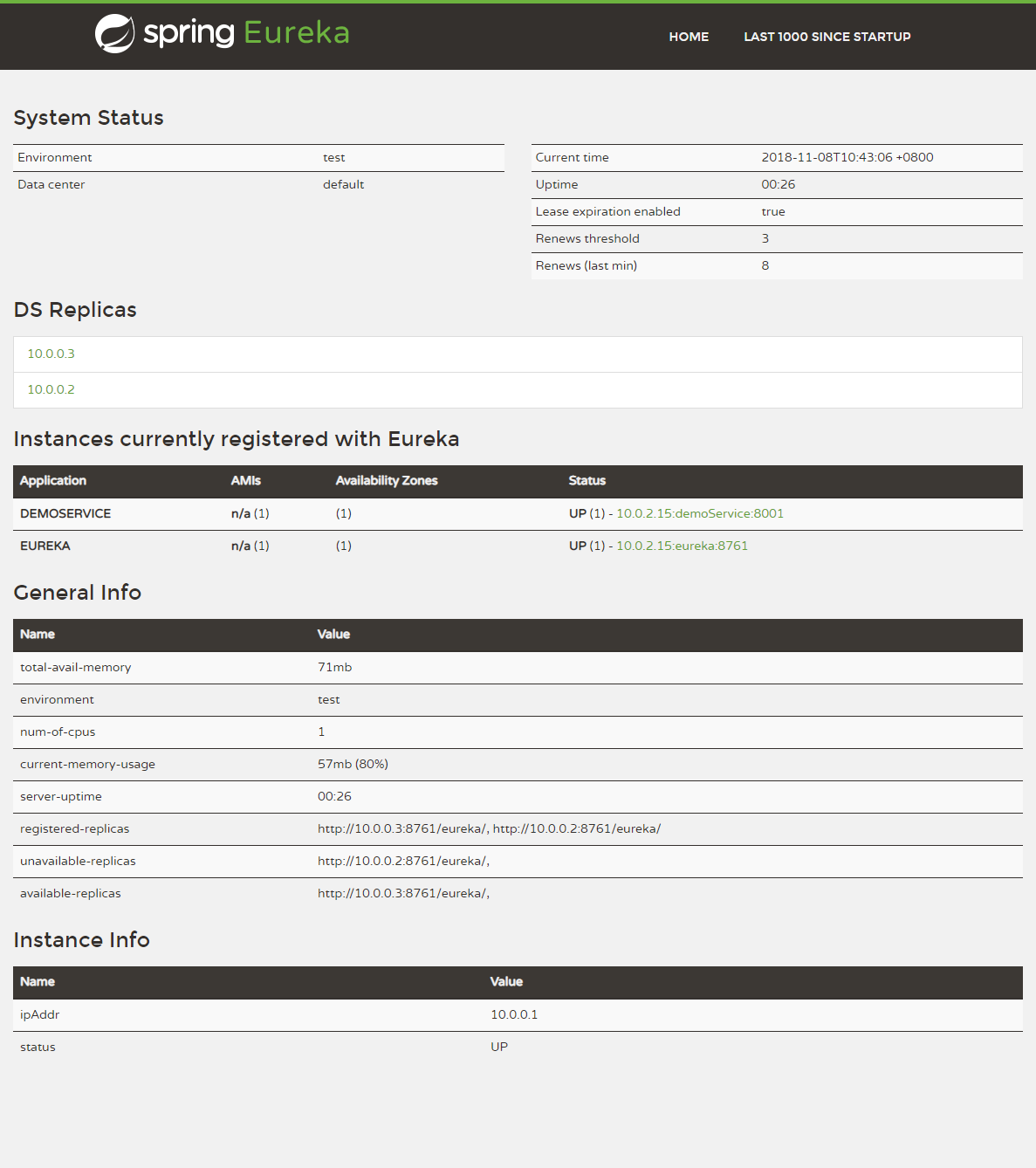
Eureka界面:
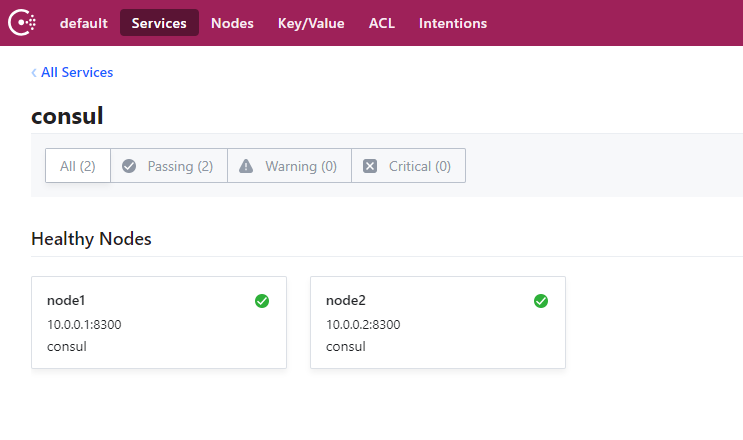
Consul服务管理界面:
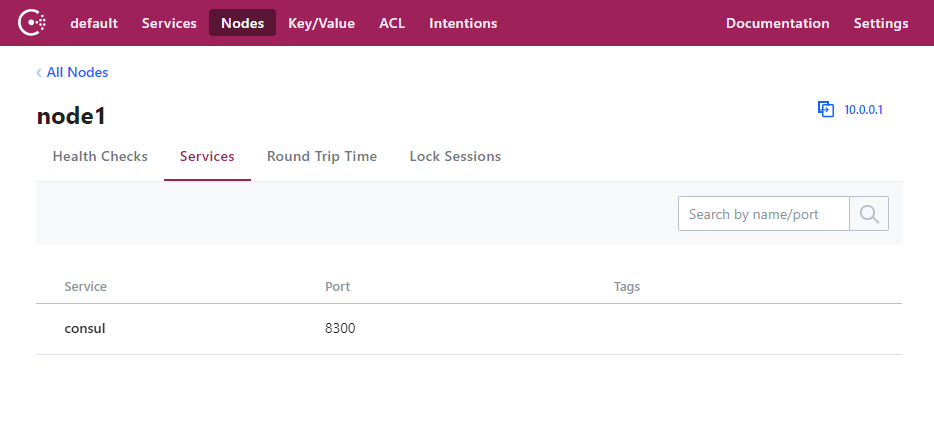
Consul节点管理界面:
RPC调用
SpringCloud的RPC调用比较单一,除了在http client可以有Apache的httpclient和OKHTTP之外没有其他额外的选择。所以这个章节我们主要是了解几个组件的特性和一些最佳实践,以下整个RPC的调用流程,我们也能从中看到各个组件的职责:
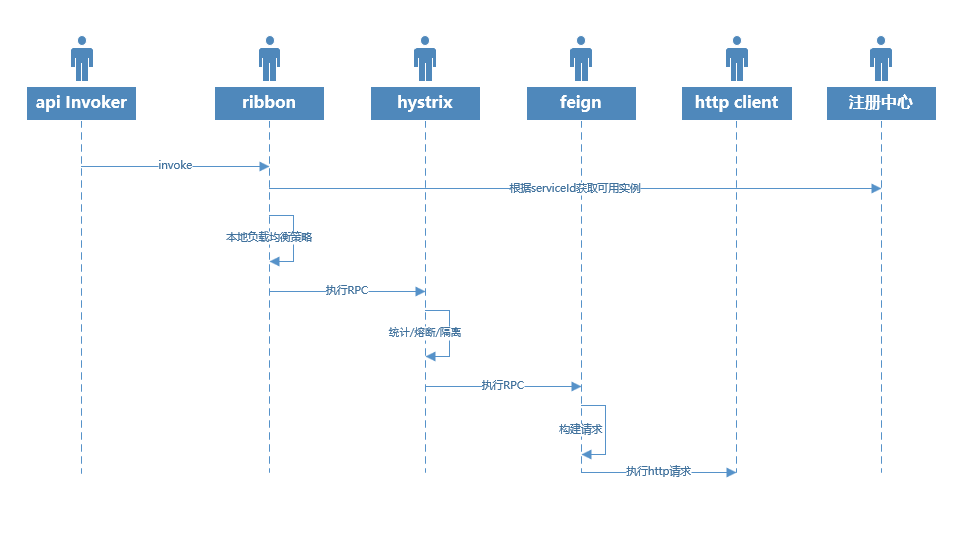
另外,SpringCloud的大部分组件均依赖于Netflix的Archaius组件(配置的动态管理),即需要获取配置属性的时候,不是像传统的直接读取对象中的某个属性,而是每次均从配置容器(System.Prrpertity,Spring的Environment,自定义的配置容器等等不同层级的配置容器)重新获取,实现配置的动态更新。
ribbon
ribbon是SpringCloud负责负载均衡的组件,其主要的职责是:
- 定时将订阅的服务的实例信息更新到本地缓存,以便后续使用
- 定时的与不同实例进行健康检查(默认为ping),并剔除不可用的实例
- 在多个实例之间按照一定的策略进行负载均衡控制
所以在ribbon这一层,主要是控制负载均衡策略的选择。ribbon默认提供几个主要的负载均衡策略:
- RoundRobin:轮询
- Availabile:可用性
- Weight:自定义比重
轮询为是使用最为广泛的负载均衡策略,也是最简单的负载均衡策略,好处是不用引发雪崩,坏处是如果某些节点健康状况不是很好的话,会影响整个集群的性能。
我们曾经做过一次全链路压测和优化,通过链路跟踪定位性能比较差的瓶颈然后做一些优化。做了好几次临时上线去做我们认为可以提高性能的patch,耗时10+小时,但是总是不能让人满意,最终在凌晨的时候我们下线了几个性能明显较差的节点,结果整个链路的tp90/95/99都变得非常好看,而整体负载也上升很明显。
而可用性是一种更加高级和复杂的负载均衡策略,会从多个维度去计算节点的健康度/可用性,然后将流量更多的引导向指标更好的节点。但是这也有一个隐患,即如果没有中心节点做整体流量的调控,节点之间无法进行有效的协调,则有可能因为自己的流量在一个时间被集中导向某一个节点,引发雪崩。而这种情况随着集群规模的扩大出现的概率也随之增加。
而在实际环境中,我们更多的是使用轮询作为负载均衡策略,通过引入第三方监控来监控RPC的性能情况,当发现性能有问题的节点的时候,则重启或者下线节点。
ribbon需要配置内容较少,其配置内容格式主要为:
<clientName>.<nameSpace>.<propertyName>=<value>
例如:
userService.ribbo.ReadTimeout=1000
如果是全局的默认配置,则不需要clientName,例如:
ribbo.ReadTimeout=1000
hystrix
Hystrix在SpringCloud中主要承担CircuitBreaker(即断路器)的职责,主要是负责:
- 对历史调用记录进行统计
- 根据规则对不同的业务进行隔离,限制资源占用
- 根据规则判定断路器执行状态
- 当触发断路器后,执行降级策略(如果存在)
Hystrix的实现细节具体可以参考 官方wiki ,对于Hystrix整个体系的特性和实现细节均有详细的描述,当然由于整个Hystrix都是基于RxJava,所以如果对RxJava比较熟悉的话有助于理解Hystrix。在这里主要是提供一些最佳实践。
隔离模式的选择
Hystrix有两种隔离模式:
- 线程池(Thread Pool)
- 信号量(Semaphore)
线程池比较常见,信号量可以认为是类似于令牌桶的机制,每个请求开始的时候会申领一个令牌,执行完毕则将令牌返回令牌桶,和线程池的最大区别是信号量模式的时候在执行过程中不会做线程切换,这意味着信号量对于timeout缺乏支持(依赖于实际的RPC实现),会阻塞主线程(例如tomcat/netty的work线程),极端情况下会使执行线程全部耗尽导致服务不可用。所以在官方的文档中,对于隔离模式的选择主要是:
- 尽可能的选择线程池来进行业务隔离,除非你对服务方非常信赖
- 如果确实需要使用信号量隔离,那么建议对于新业务使用线程池进行隔离,当业务已经稳定和成熟的时候,再切换到信号量(Hystrix可以针对每个服务单独配置隔离模式)
同样,我们在实际环境里面也基本遵循这种规范,虽然绝大部分http client(不论是Apache的httpClient还是okHttp)都自己实现了timeout机制,但是作为断路器还是不会完全信任http client,这种对于任何其他依赖都不能完全信赖的原则也基本贯穿我们的始终(这也就是推荐甚至强制所有外部交互接口都需要进行强验证的原因)。
同时线程池还可以做一定的冗余策略,在1.5.9之后,Hystrix支持了线程池的coreSize/maxSize,再结合本来就支持的queue size,使得线程池有一定冗余空间,能够应对一些小规模的突发状况,例如小规模的网络震荡或者full gc等待,使得RPC调用更加平滑。
线程池/信号量容量规划
不论是基于线程池还是信号量做资源限制和隔离,都需要进行一定的容量规划,如果容量过小,则很容易资源耗尽,导致本来通畅的业务变得不可用;如果容量过大,一方面会浪费一定的资源,在极端情况下甚至会耗尽整个JVM的资源,影响整个JVM的稳定。以下是Hystrix的推荐容量规划:
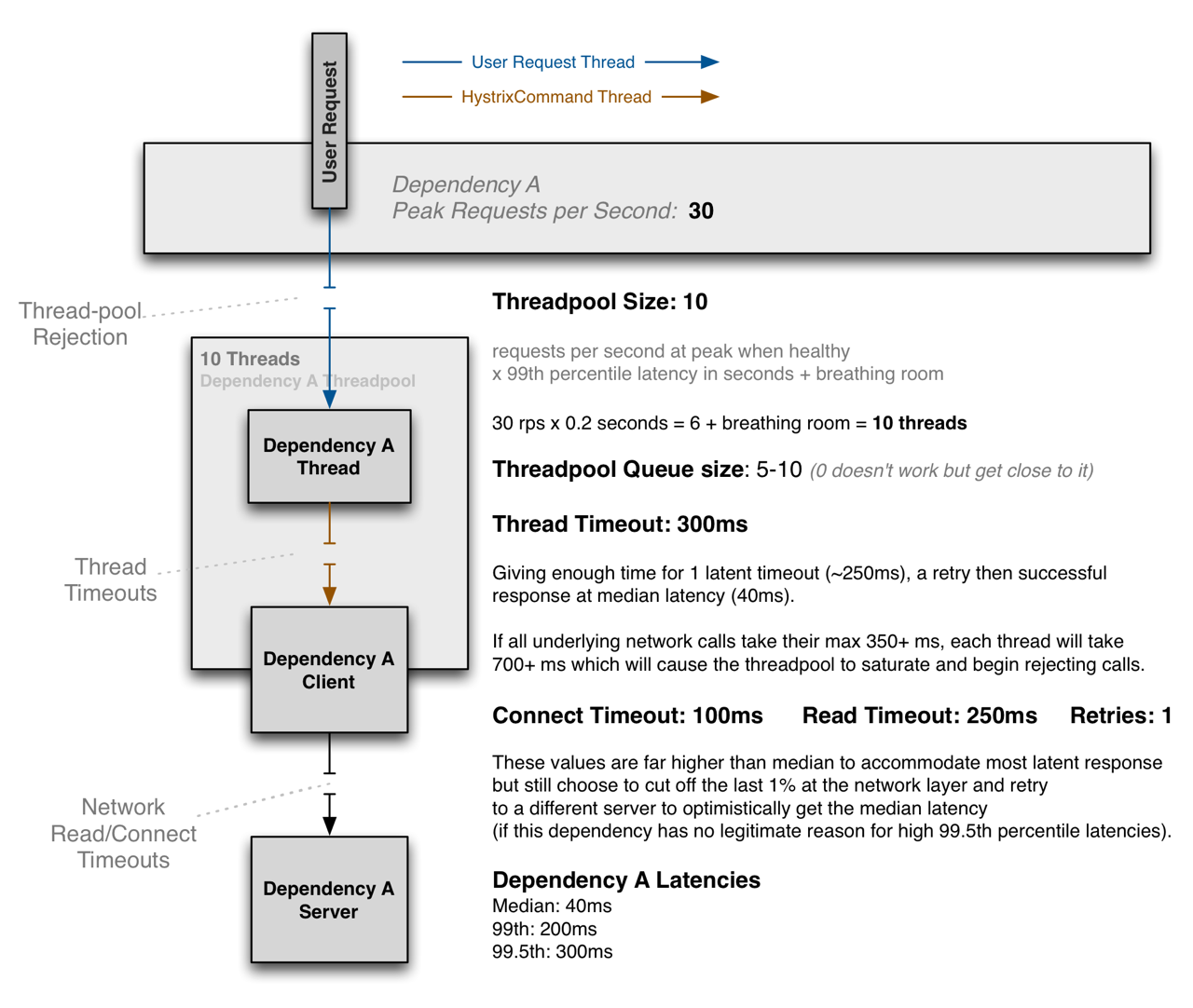
不过在实际生产环境的配置中,我们往往都会设置相对较长的超时,例如1000ms,甚至3000ms,主要目的不是为了应对网络震荡,而是一些关键资源的竞争,例如数据库;而重试我们也是默认关闭,除非我们确认上游业务确实完全保证了幂等,同时业务也确实有这种需要,否则应该考虑使用其他的补偿策略。
在Hystrix中,线程池或者所有的Hystrix配置的粒度都是服务,如果没有对服务进行单独配置,则使用默认配置,所以不论是否按照官方的范式或者自己单独进行容量规划,都需要对自己的调用频率和对于服务的耗时有充分的了解,这样才能进行针对的配置。
在Hystrix的实现中,各个服务通过ThreadpoolKey来标记独占的线程池,然后通过不同的key进行隔离。所以一般会有两种隔离策略:
- 如果依赖的服务低于20组,那么一般均是通过默认配置+少许服务单独配置的方式进行隔离
- 如果依赖的服务数量非常大(例如使用Zuul作为网关使用线程池隔离),那么给每一个服务,那么各个线程池中的缓存的线程累加起来将会达到一个恐怖的数字,那么这个时候一般则会通过服务分级,例如0级服务最优先,1级服务其次等等,这样优先保证核心服务的稳定
断路器开闭规则的设定
首先是断路器的状态模型:
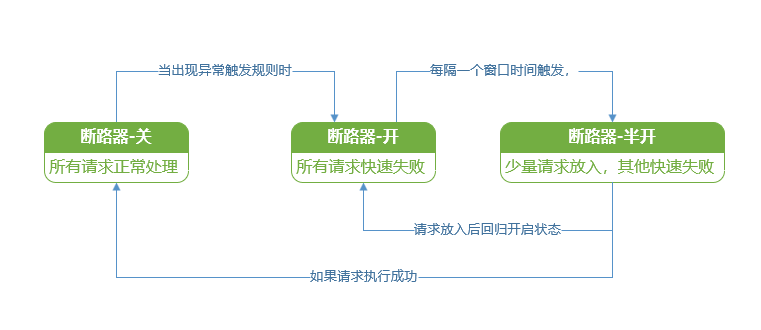
从状态机就可以发现,需要配置的主要是两个维度:
- 断路器触发开启的规则
- 断路器的时间窗口
断路器的尝试窗口时间为5秒,这个一般问题不大,主要集中在断路器的触发规则上:
- 断路器生效的最小并发数量
- 失败率
总体还是需要了解自己对于所依赖服务的调用频率和可容忍限度来进行配置,大部分还是基于默认即可。
基于微服务的降级策略/基于业务的降级策略
虽然不论是feign亦或是Hystrix均提供了降级策略的callback接口,不过在实际中我们依然很少使用,因为java的异常捕捉机制更适合处理异常,特别是在有标准的异常处理规范的基础上。所以大部分场景中我们应该都完全不会使用SpringCloud提供的降级策略,而是通过更加完备的异常捕捉机制来进行冗余/降级处理。
OpenFeign
Feign更像是一套HTTP client的规范,类似于SLFJ和log4j/logback的关系(实际上还包括很多的标准流程,是标准流程+SPI的设计模式),所以我们更关注它的几个主要实现:
- URLConnection:每个节点会保持一个长连接,但是没有连接池,只能顺序执行没有并发
- Apache的httpclient:Apache开源的实现,有连接池,超时等特性
- OkHttp:在Android开始流行起来的实现,支持很多新的特性(例如HTTP/2)
一般我们都会使用httpclient或者OkHttp,两种的稳定性和性能都是久经考验,差距也不是太大。配置方面也主要是一些连接池和超时等限制,这里要注意的是当集群规模比较大的时候,连接池过大会浪费服务器的连接句柄。
其他扩展组件
actuator
actuator是SpringBoot的一个开箱即用的基于web的系统监控和管理模块。一方面能够实时查看Spring生态中的很多信息,包括各种配置信息、运行时状态信息(例如bean、web请求、其他cloud组件状态等待),一方面能够提供一些简单的控制功能。详情可以参考 官方文档 的actuator章节
值得注意的是actuator自身的安全控制比较弱,主要依赖于SpringSecurity,如果没有使用SpringSecurity(可以只使用单机的username/password模式),则完全没有安全控制的渠道。所以如果不使用SpringSecurity,则只能考虑通过端口屏蔽来解决:actuator和SpringMVC不使用同样的对外端口,业务通过Nginx暴露,而actuator端口在Nginx上则对外暴露,只允许内部访问,需要配置:
management.server.port=xxx
Sleuth
sleuth主要是负责SpringCloud的链路跟踪,其原理相对比较简单,其主要原理为:
- 进程内部链路跟踪:通过SLFJ的MDC机制(类似于ThreadLocal),实现全流程的执行过程跟踪
- 进程间的链路跟踪:通过HTTP Header来传递链路跟踪信息
sleuth只是负责链路跟踪的记录,并不负责后续的采集、合并、分析、展示,一般还会搭配Zipkin,但是Zipkin功能单一而且扩展性比较小,很少在生产环境中会使用。所以一般要么是将sleuth桥接在其他监控系统上,要么是采用其他的链路和方法调用解决方案,弃用sleuth。
Hystrix dashboard/turbine
SpringCloud可以通过dashboard汇总客户端的Hystrix监控数据来进行监控(Hystrix可以暴露一个steam接口),来进行集群的批量监控。但是不管是dashboard还是turbine本身都是非常简单的实现,离真正可用差距还较大:
- 数据来自steam的http接口,没有在本地进行汇总处理,如果集群数量较大(超过100个实例),对于dashboard或者turbine汇总服务的网络带宽压力很大
- 没有历史回溯,只能查看最近一个窗口的统计记录,这对于想回溯或者根据最近记录排查问题是一个死结
- 本身监控维度和人机交互的接口离一个真正的APM系统都相差甚远
结论
针对上诉的测试情况,所以我们的技术选型的结果如下:
- 注册中心:Consul集群 (为后续的部署和服务分离做准备)
- RPC组件:Ribbon + Hystrix + OpenFeign + Apache Httpclient (标准使用)
- 监控管理:SkyWalker + SpringBootAdmin (JMX远程管理)
整套解决方案最佳实践会在demo中进行体现,并组织代码review和讨论来确定最终方案。